참여 : 반치용, 반영훈
인터넷에서 공무원들 지출 내역으로 맛집찾는 내용이 있는데... 너무 수박 겉핥기 식이라 조금 더 잘 찾을 방법을 찾아보았다.
다른데서는 그냥 집계만 한 것 같네요. : https://news.joins.com/DigitalSpecial/305
좀 아쉬워서 새로 시도해봅니다.
[내꺼]
일단 만들었으니 링크
https://github.com/banchiyong/jmt
만드는 과정이랑 소스코드는 천천히 공개할 예정.. 어제 12시쯤부터 시작했으니 6~7시간정도만에 만든듯... 어휴 여기저기서 에러 많이나서 상상한 것 보다 훨씬 걸렸네요... 어후... 게다가 초반에는 블로깅을 위한 과정 하나 하나까지... ㅜㅜ 힘들었습니다.. (막상 들여다보니 손봐야할 것들이 많네요...)
들어가보시면 점이랑 선이 있는데,
점(node)이 지출내역의 각 부서(흰색) 및 매점(나머지색, 붉은 색일수록 더 빈번하게 찾은 집/하늘색이 덜 빈번하게 찾은 집)입니다. 선(edge)은 어느 부서가 어디로 갔는지를 표시해주죠.
워낙 매점이 많아 제 노트북의 부담을 덜기 위해 최소 30번 이상 찾아간 매점만 표시했습니다. 다음번엔 기준을 좀 더 높여봐야겠네요..
일단 concetric 레이아웃으로 먼저 보겠습니다.
1. layout -> concentric
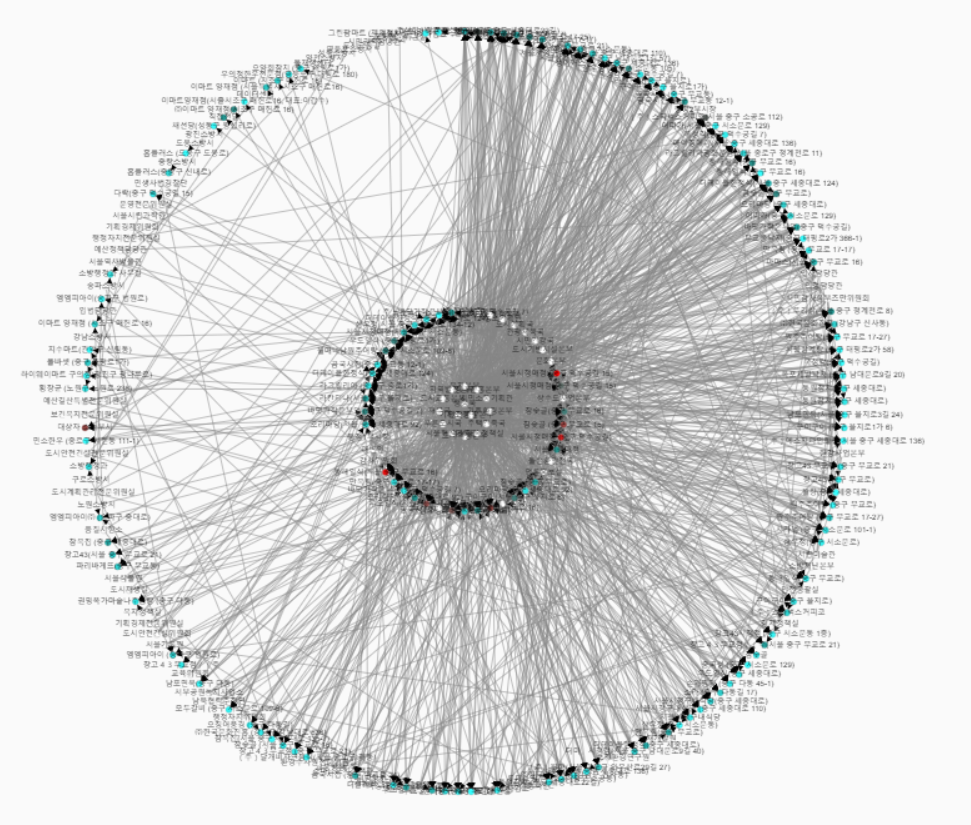
- 센터로 갈 수록 연결이 많이 되어있지요.
2. 가운데를 보면 붉은 색이 모여있습니다. 데이터상에서 가장 많이 찾아간 곳입니다. (보통 다른데서 분석하면 나오는 곳이 저기입니다.) -보기좋게 붉은 점들만 드래그 해서 따로 찍었습니다.
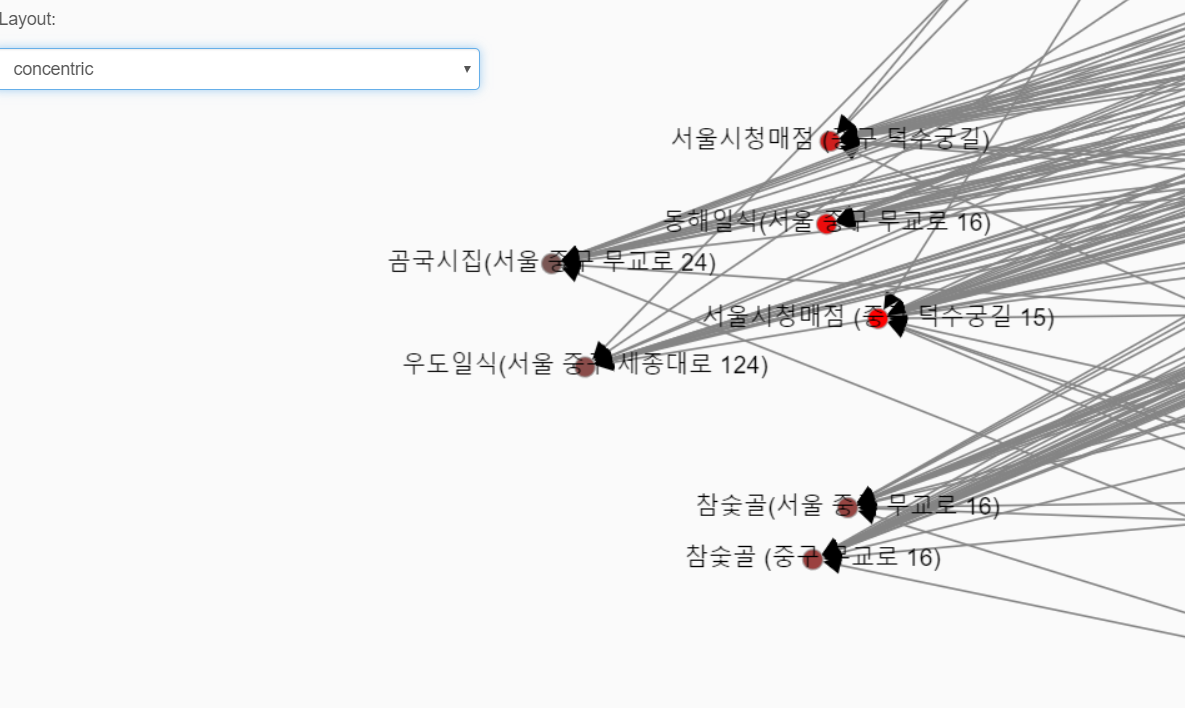
1) 서울시청매점이 압도적으로 붉은 색이고, 두 개나 있네요... 부처마다 사용처 주소 입력 양식이 달라서 따로 나뉘었네요. 일일이 손으로 다룰 수 없는 빅데이터이다보니... 저런건 일일이 다 거를수가 없네요 ㅜㅜ 여튼 압도적입니다.
2) 그 뒤로 [동해일식], [참숯골](합치면 동해일식보다 많을 것 같은데.. 실제 데이터를 들여다보면...
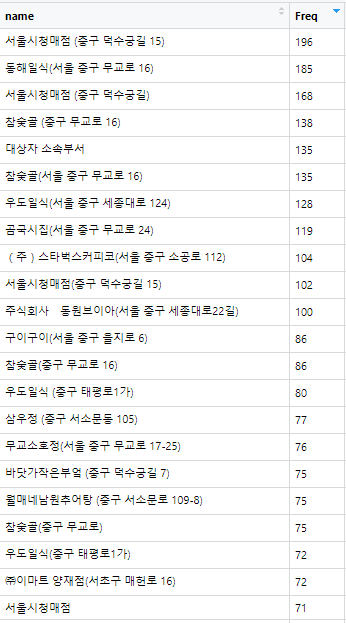
상위 기준으로만 이정도 중복이 있습니다. 조만간 중복 제거 코드도 만들어서 좀 합쳐야겠네요.
대상자 소속부서는 뭔지 궁금하네요.
여튼 위 리스트가 일반적인 자주가는 곳 리스트 입니다.
3) 센터를 좀 더 자세히 볼까요?

가운데에 있는 부서들이 허브라고 볼 수 있습니다. 여기저기 음식점을 많이 돌아다니는 부서입니다! 저 부서분들이 맛집을 잘 아는것이거나, 여기저기 도전을 많이 하는 분들이라고 볼 수 있겠죠?
행정국 뒷조사를 해 볼까요?
총무과랑 행정국 총부과가 나뉘는데... 매서운 눈초리로 비교해 보니 10월까지는 행정국 총무과고, 11월부터는 그냥 총무과 입니다. 담당자가 업무처리가 귀찮아졌거나... 담당자가 변경되거나.. 뭔가 사정이 있겠죠? 그리고 행정과의 업무가 자동화가 제대로 안되었다는 의미이기도 합니다.
여튼
사용처에 0이랑 값 없음이 있어서 봤더니 경조사비 및 유족 사망위로금이었네요. 삼가 고인의 명복을 빕니다.
여튼 행정국에서 찾아간 음식점들을 볼까요?
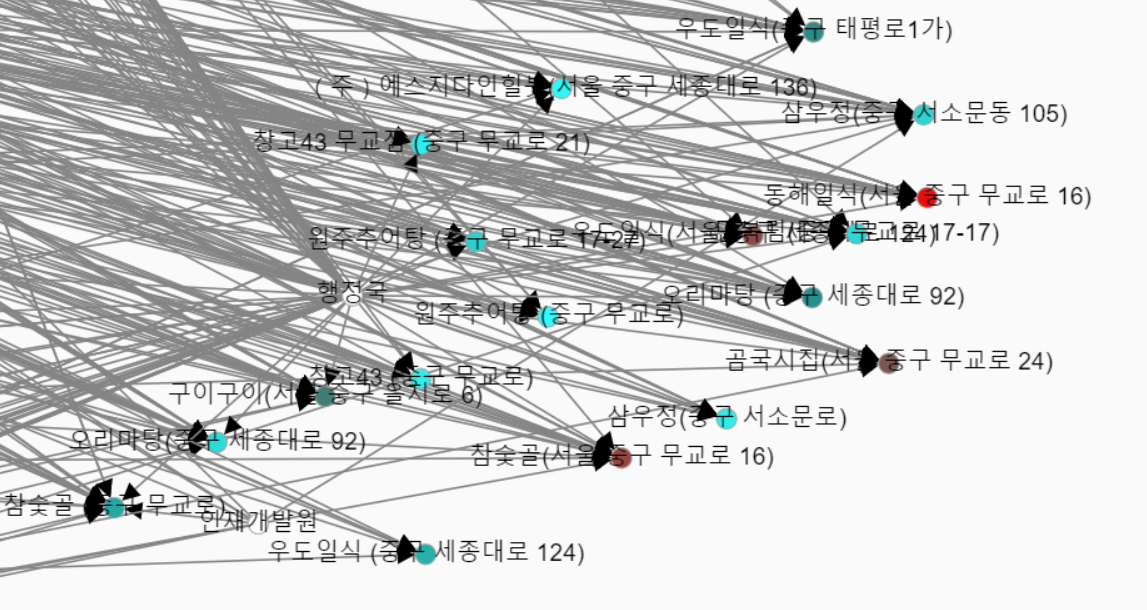
다 하려다가 너무 많아서 포기했습니다. 저기 누군가는 이집저집 많이 찾아다니시는 분이신가 봅니다...
맨 바깥쪽 오전 6시~12시 부분이 제일 적은 곳입니다. 그 중 소방서가 눈에 띄어서 보았는데...
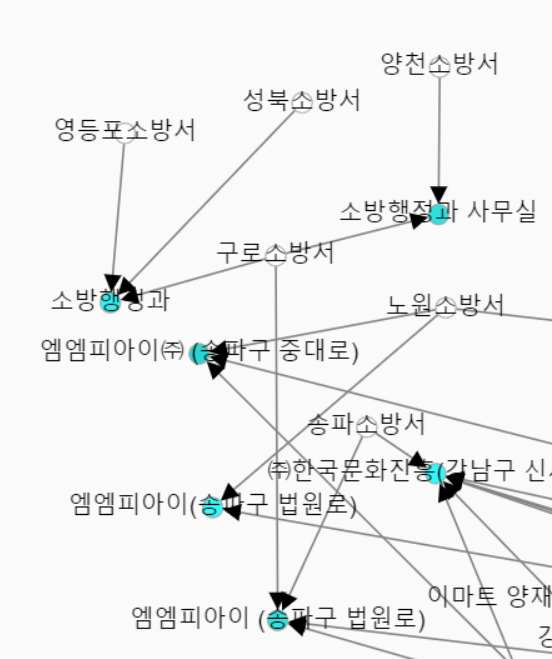

소방서 추진비 예산이 부족한건 아닐까... 의심스러울 정도의 사용 내역이네요.
3. 여기서 끝내면 시시하죠...
1) 사람마다 취향이 다를텐데... 본인이 맛있게 먹었거나 마음에 드는 곳이 있으면 그 점을 끌어다가 옆에 둡니다.
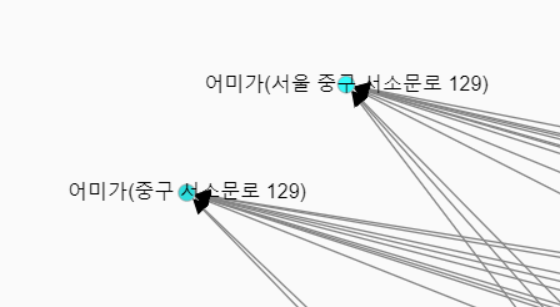
그 다음 이걸 먹은 사람 혹은 부서들을 찾아냅니다.
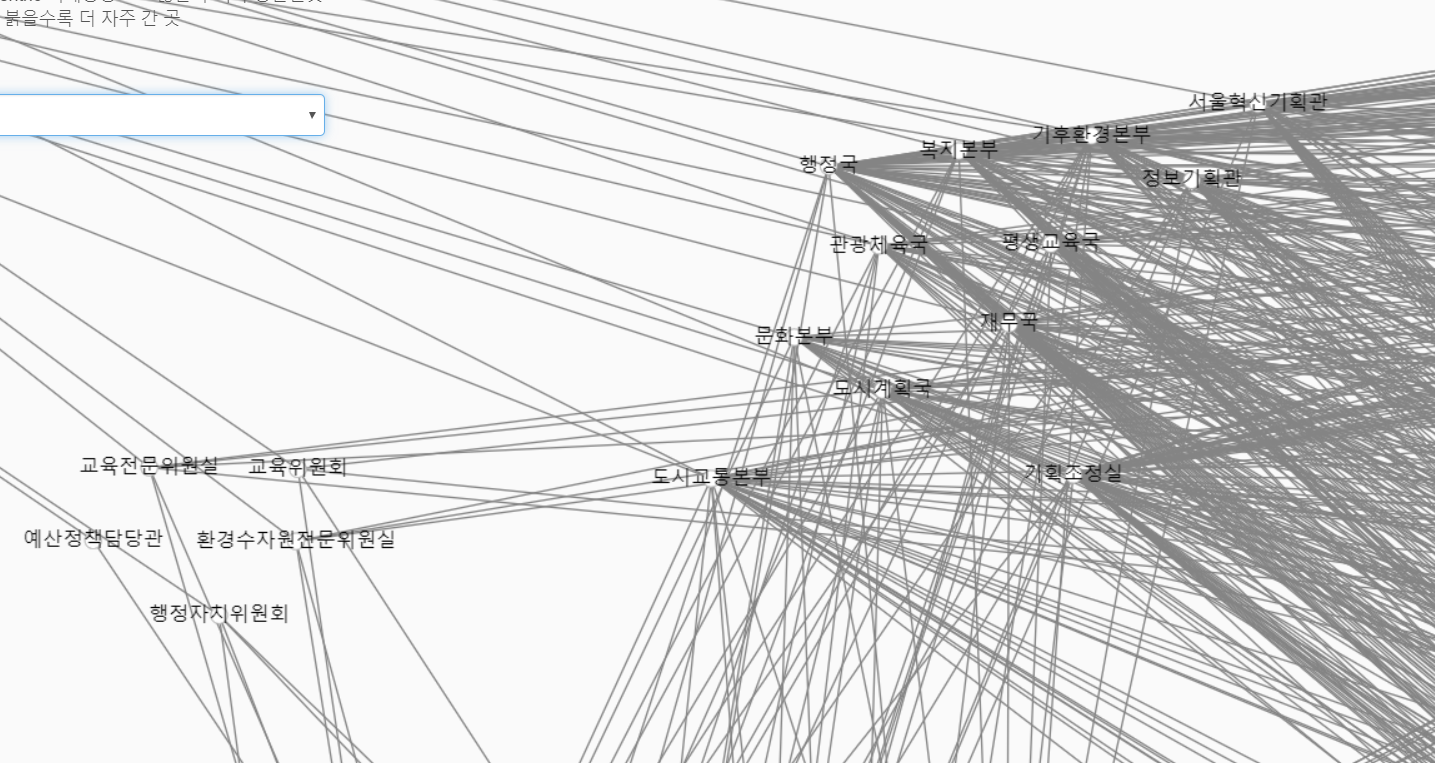
왼쪽의 5군데는, 여러군데를 다니지 않는 부서입니다. 행정국 근처에는 선이 많은(많은 곳을 다니는 부서) 부서를 모아두었습니다.
- 여러군데를 다니는 쪽은 여러군데를 다니니 운좋게 겹쳤을 가능성이 높지만, 반면 왼쪽 부서들이 겹치는 식당은 취향이 겹칠 가능성이 높죠. (여러 변수가 있습니다.)
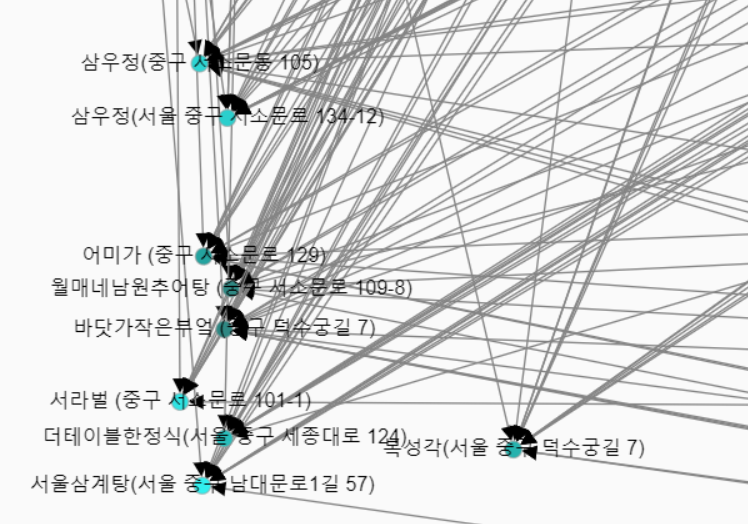
>> 왼쪽 분들이 겹치는 곳 리스트입니다. 처음 시작에서 선택한 어미가도 나오고, 실제로 조사해보면 비슷한 취향의 매장일 가능성이 높을 것 같습니다.(얼핏 이름만 보았을 때)
- 반면 오른쪽은 많은 곳을 다녔기에, 저 분들이 많이 간 곳은 일반적인 '맛집'이거나 '가성비'가 좋은 곳일 확률이 높습니다.
이쪽은 데이터를 좀 더 보겠습니다.
아까 잡았던 행정국으로 보겠습니다.. 총 3632건 밖에 되지 않기 때문에 그냥 엑셀로 작업했습니다.
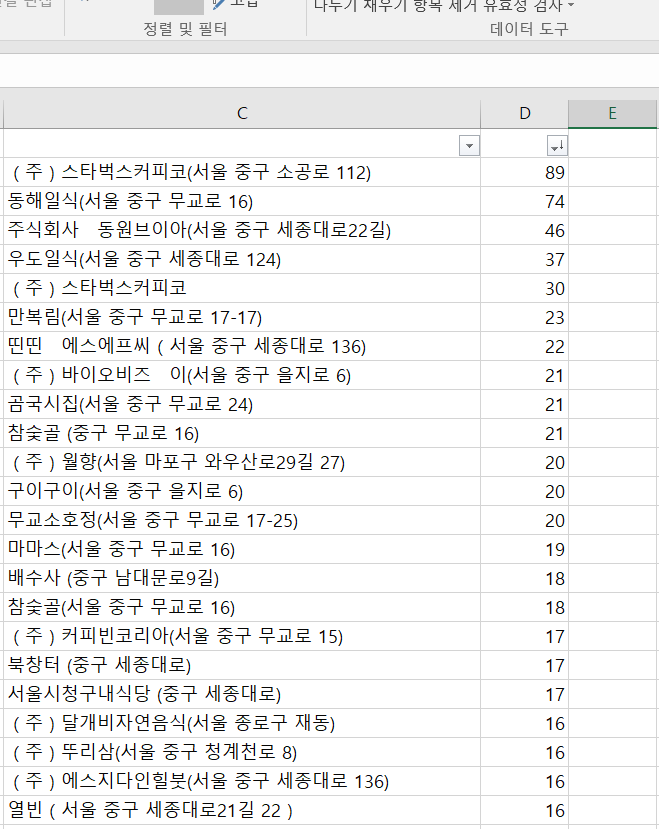
여기 상위권이면 일반적인 기준에서의 맛집들일 가능성이 높습니다.(여기저기 다니는 만큼 관심도 많은 사람이 자주 가는 것이니까요.)
하지만 또 다른 포인트는 횟수가 1회인 곳들입니다.
좋은건 공개해도 되지만... 안좋은건 공개하면 괜히 큰 피해를 끼칠 수 있으니 공개는 하지 않겠습니다.
추가로 이 데이터는 일부 지역에 쏠림현상이 있습니다. 때문에 편향에 대해 조심해야 하고, 횟수가 적은 곳이 있다고 하더라도 타지에 있는 곳(강원도 등...)인 경우 맛있어서 두번 가거나 하는 경우도 있으니, 절대적인 지표라고는 볼 수 없습니다.
개인적으로 사양좋은 컴퓨터와 카드사 데이터가 있으면 훨씬 정밀한 맛집지도를 그릴 수 있을 것 같은데... 개인 취향별로 근처 맛집 추천 서비스같은것도 가능하지 않을까 싶습니다.
아쉬운점 : 같은 장소가 표시 방식에 따라 다른 경우가 많음. 정규식으로 어느정도 줄여보다가 너무 노가다 작업이고 시간이 걸리는 것 같아서 하다가 정지함...
블로그 글에는 포함되어 있지 않지만 코드는 공유해 두었음
https://github.com/banchiyong/jmt
banchiyong/jmt
Contribute to banchiyong/jmt development by creating an account on GitHub.
github.com
'Projects > JMT project (공동)' 카테고리의 다른 글
| [Day-00]데이터 분석 맛보기 프로젝트 (0) | 2019.08.24 |
|---|

댓글