판다스의 대표 데이터셋인 붓꽃데이터셋으로 K-Means를 이용하여 클러스터링을 해 보겠습니다.
우선 사용할 라이브러리와 데이터들을 불러와주고
kmeans를 어떻게 수행할 것인지 세팅해줍니다.

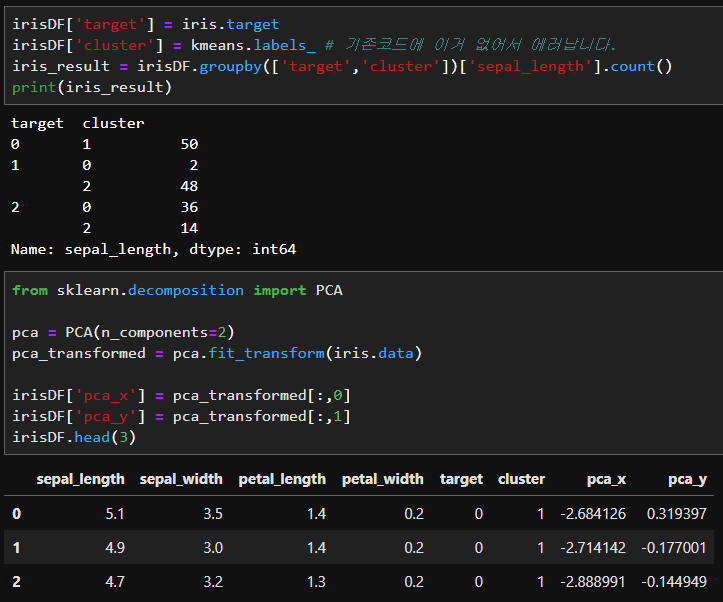
데이터프레임에서 타겟와 클러스터를 정해주고 groupby와 .count를 이용하여 정리해주고
fit_transform을 이용하여 평균과 표준편차를 계산하여 정규화 해 줍니다.
각 클러스터별로 별도의 인덱스로 추출하고 해당index로 각 클러스터의 pca_x, pca_y값을 추출하여 세가지 형태의 marker로 표시해 줍니다.

추가로 알고리즘 테스트를 위한 데이터를 생섭합니다

산포도를 marker별로 생성하여 시각화 해 줍니다.

클러스터링을 해준 후 중심위치 좌표 시각화를 위해 센터값을 구한 뒤 군집된 Label 유형별로 나눠서 marker별로 산포도를 그려주고 이전에 구했던 중심위치좌표를 시각화 해 줍니다.

해당 포스트는 위키북스의 파이썬 머시러닝 완벽가이드를 참고하였습니다.
'반영훈 > Python' 카테고리의 다른 글
| 파이썬으로 하는 차원축소 (0) | 2020.08.02 |
|---|---|
| [ML]파이썬으로 하는 선형회귀 (0) | 2020.08.02 |
| [아나콘다] python 버전 변경 하는 법 (2) | 2019.11.01 |
| 주피터 노트북에서 package 만들고 import 하기. (0) | 2019.09.16 |
| [웹 코딩사이트] (0) | 2019.09.09 |


댓글