groupby 함수 사용법
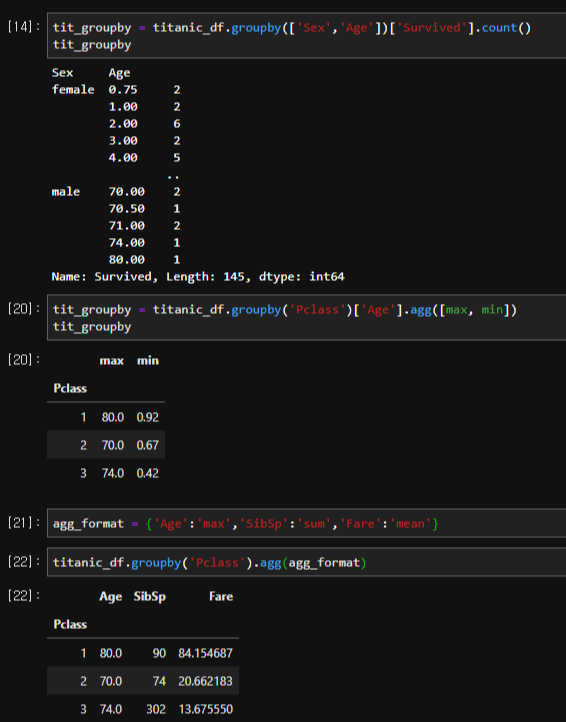
데이터 프레임명.groupby(분류를 나눌 열 이름)[연산을 할 열 이름].집계함수()
형태로 사용하는 것을 볼 수 있다.
연산할 열 별 집계내용이 다를 시 agg() 함수 안에
{'열이름':'집계함수명,'열이름':'집계함수명' .... } 형태로 넣으면 열별로 별도의 집계가 가능하다.
처음 파이썬으로 전처리 할 때, pandas를 몰라서 줄 단위로 불러들여서 구분기호로 split하고, 각각을 리스트에 넣어서 연산했었는데... 시간은 정말 많이 잡아먹고 오류는 많고 ㅜㅜ...
이걸 좀 더 일찍 알았으면...
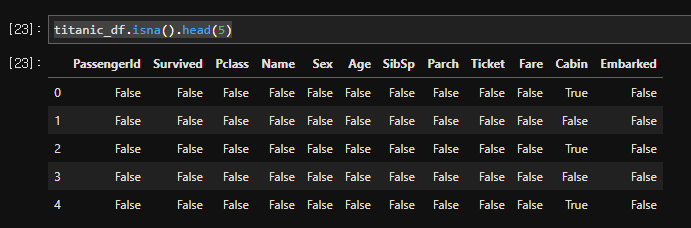
결측값 핸들링(결측값 제거, 수정 등)
데이터프레임.isna() 를 통해 결측값에 대한 행렬을 데이터 프레임 형태로 리턴 가능함
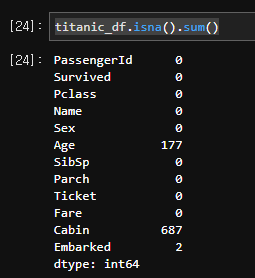
.sum() 을 이용해 각 항목(열)별로 몇 개의 결측값이 있는지 확인 가능하다.
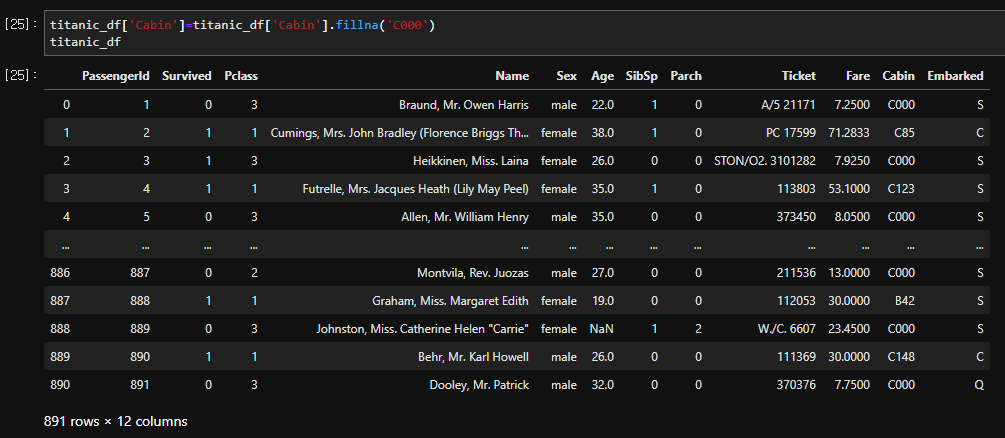
결측값을 변경하기 위해 .fillna() 를 사용할 수 있다. 제거를 원한다면
.fillna('')
라고 입력하면 된다.
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')결측값을 해당 항목(열)의 평균으로 넣는 코드와 특정 값'S'로 채워넣는 경우의 코드
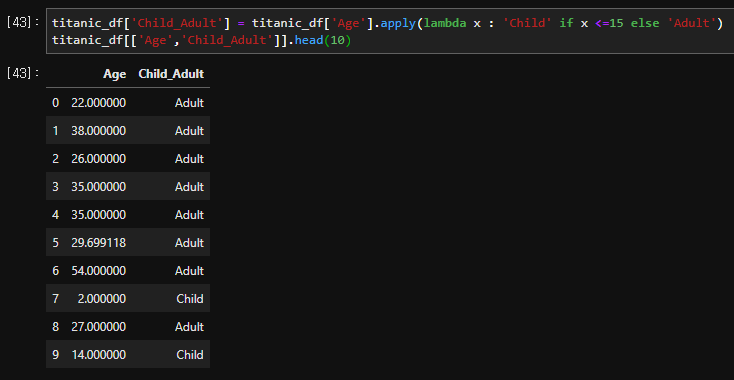
lambda와 apply를 이용해 조건부로 열을 채워 넣는 방법이다.
조건에 따라 0,1을 구분해 넣을 때 많이 사용하는 코드이다.
titanic_df['Child_Adult'] = titanic_df['Age'].apply(lambda x : 'Child' if x <=15 else 'Adult')
titanic_df[['Age','Child_Adult']].head(10)더 복잡한 조건에서는 별도로 함수를 선언하여 보기좋게 처리하는 방법도 있다.
def get_category(age):
if age <= 5 : cat = 'Baby'
elif age <= 12 : cat = 'Child'
elif age <= 18 : cat = 'Teenager'
elif age <= 25 : cat = 'Student'
elif age <= 35 : cat = 'Young Adult'
elif age <= 60 : cat = 'Adult'
else : cat = 'Elderly'
return cat
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : get_category(x))
titanic_df[['Age','Age_cat']].head(10)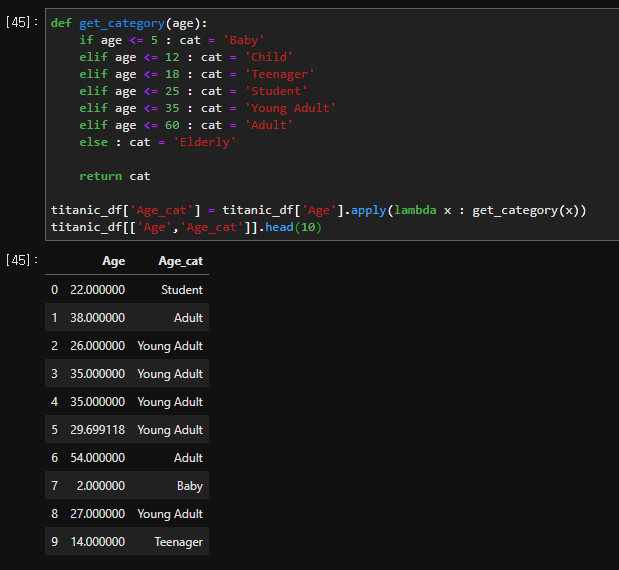
pandas도 일단락 되었다.
기본적인 데이터 핸들링 기술을 익혔으며, 이 것이 전처리의 기본이 될 것이다.
'반치용 > 기타 및 저장' 카테고리의 다른 글
| [저장]예제코드(한빛) (0) | 2019.12.26 |
|---|---|
| [논문 리뷰]Bidirectional association betweengastroesophageal refux diseaseand depression: Two diferentnested case-control studies using anational sample cohort (0) | 2019.12.26 |
| 생존분석 & P-value 등 (0) | 2019.12.23 |
| [파이썬 머신러닝] day 002 - numpy 이어서 + pandas (판다스) (0) | 2019.12.16 |
| [논문]Network Decomposition into Fixed Points of DegreePeeling-필링(Peeling) 관련 (0) | 2019.12.16 |

댓글