<참고> 태블로를 써보지 않았으므로, Qlik 대비 경험을 적었음. Qlik도 깊이있게 써보지 않아서 상당히 편향적이고 주관적일 수 있음을 말머리에 미리 적어둠

사족으로 시작! 요즘은 이런것도 있구나... 싶었음.
시간표는 관심있는 사람만 볼 수 있게 접어뒀습니다.

BI툴을 찾는 사람들이 많아지는 것 같고, 데이터 분석 직무자는 BI툴 사용 경험도 채용시 영향을 주기도 한다.
현재 업계 1위는 태블로 인 것 같고, 2위가 Power BI, 3위가 Qlik 인 것 같다.
업무하면서 (주)미소정보기술 과의 협업을 위해 Qlik을 배워서 간간히 써 왔는데, 오늘 Power BI 밋업 후에 거의 Power BI로 마음이 넘어간 것 같다. (Qlik으로 작업하는 곳 자체가 흔치 않은 것 같은데, 저기서는 이것저것 뚝딱뚝딱 잘 만들어 내더라)
단점 : 우선 단점부터 집고 넘어가겠다.
1. 메뉴가 복잡하다. 기능이 너무 많다보니 인터페이스가 너무 복잡함. 어떤 건 왼쪽 슬라이딩, 오른 쪽 슬라이딩은 계단형에 접이식... 심지어 왼쪽 슬라이딩은 해당 영역 외에 클릭해도 사라지지 않아서 좌상단 화살표를 눌러야만 사라진다.
아직 최적화가 덜 된 상태로 계속 기능 업데이트가 되다보니 점점 복잡해지는 것 같다. 이건 시간이 해결해 줄 것 같다.
2. 파일 불러오기를 통한 데이터 분석시 참고 데이터에 대한 상대경로 설정이 지원되지 않는 듯 하다.
(혹은 있는데 강사분께서 모르시는 건지도 모르겠다.)
보고서 파일에 들어간 데이터끼리는 별 문제 없는데, 다시 불러오는 과정에서 절대경로로 참조해 오류 메시지가 뜨는 경우가 있었음.
3. 회원가입이 개인 메일 주소로 안됨 : naver , gmail 등은 안됨;; 그래서 내 도메인으로 메일주소 만들었는데 확인 메일이 아직까지 안옴...
장점 : 그런데 저거 다 씹어먹을 정도로 기능들이 마음에 들더라.
1. 환영사에서 육성환 상무님 말로는 클라우드부터(azure) 앱, BI까지 다 연동되는 구조를 염두에 두고 만든다고 하는 것 같다. azure를 기반으로 세팅중인 곳은 연계가 편할 것 같다.
> 난 azure 안써봐서 모르겠다. gcp밖에 안써봄.
2. 업데이트 내용 자체보단 속도가 솔직히 무섭더라.
http://newsjel.ly/archives/newsjelly-report/visualization-report/10419
이게 작년 9월 24일 기사다.



아래 두 개가 오늘 인터페이스다. 인터페이스가 저만큼 달라졌다는건 기능/UX변경 및 추가가 엄청나게 되었다는 거다. 큰 기업은 정말 다르구나 싶었다. 개발 하는 사람들은 엄청나게 느낄 것 같다. 5개월동안 프로그램이 저 만큼이나 변하는게 얼마나 큰건지...
3. 체감상 가벼움 : 기본 프로그램 자체가 먹는 RAM이 Qlik보다 적은 것 같음. Qlik 쓰다보면 불안불안하다가 튕기는 경우가 좀 많았는데 Power BI는 아직 못겪어봄.(단순히 큰 데이터를 안써봐서 일 수도 있음)
확인결과 프로그램 자체로는 Qlik이 조금 더 가벼움. 이전에 쓸 땐 안그랬는데 오늘 쓰니까 로딩도 Qlik이 더 빠름
4. 페이지간 연계(드릴스루, 슬라이서 동기화)의 편의성
1) 드릴스루 : 특정 시각화의 요소를 선택해서 필터링된 항목을 다른 페이지로 전달하는 것이 스무스하다.
 |
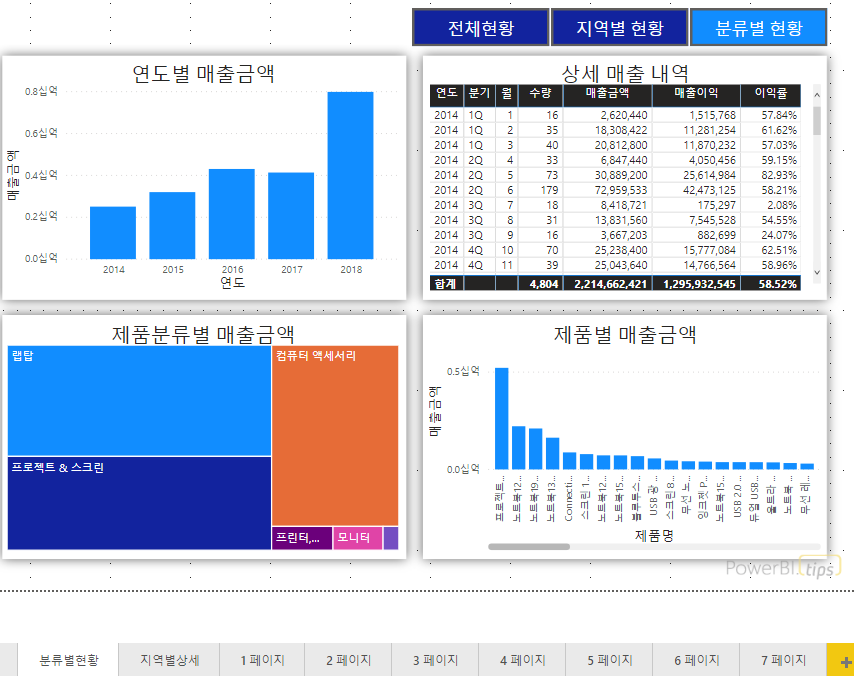 |
Qlik으로 할 때는 선택한다음에 페이지 자체를 바꿔야 했는데 부드럽게 이동하는 느낌이라 좋았다.
2) 슬라이서 동기화
슬라이서 자체가 생소했는데, 사실상 Qlik에서의 필터와 거의 같은 개념 같다.

1번이 슬라이서, 2번이 필터다. 내 생각엔 메뉴에 필터가 있어서 저거 구분하려고 슬라이서라는 이름을 붙인 것 같다.
1번이 Qlik에서의 필터 역할을 하는 도구(뷰어 내에서)이고, 2번인 필터는 시각화 요소 내/페이지 내/모든 페이지 범위에 대해 상세하게 데이터에 대해 필터링을 하는 메뉴로 보인다. (다른 툴 안써봤으면 엄청 헷갈릴 것 같고, 이걸 왜 이렇게 만들었나 싶을 것 같음)
근데 결과물은 더 이쁘게 잘 나올 것 같음. 코드로 일일이 안해도 되서 다루기도 편할 것 같음.
5. 인터페이스의 익숙함 : 탭 이동, 메뉴 구성등이 기존의 오피스 시리즈와 유사한 것이 저 복잡한 UI에도 불구하고 편했다. (익숙한 사람만 익숙함. 참가한 대부분의 사람들은 그래도 힘들어하더라...)
6. '분석' 기능
개인적으로 이게 제일 좋았다. 이거 다 수작업으로 일일이 못보는 것들이 많을텐데... 나열 해주는 것만 해도 엄청 좋을 것 같다.

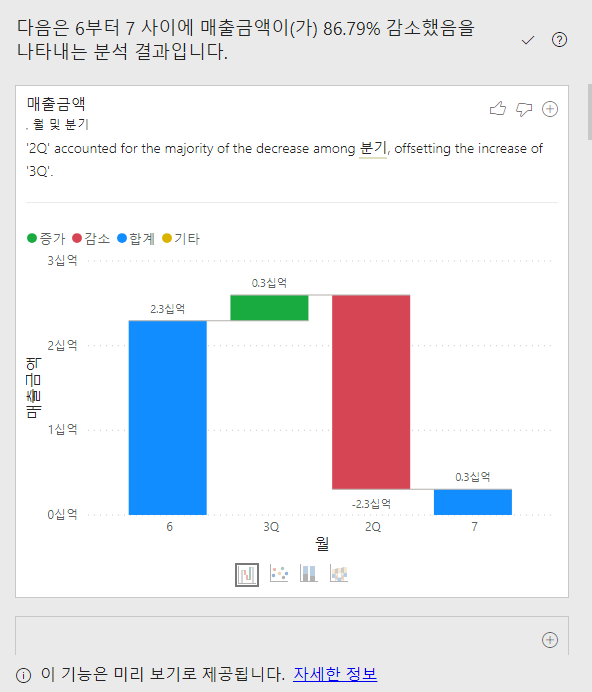
데이터를 보면 7월 매출이 급락해있는 것을 알 수 있다.
데이터 분석을 하려면 '왜'를 찾아야 할 수 있는데... 수많은 변수들은 언제 다 보냐...
그걸 쉽게 해 주더라.


 |
 |
 |
 |
음... 변수별 요인을 인공지능으로 체크해 준다는 것 같은데... 단순 회귀를 한 건지, 결정 트리 계열 혹은 다른 무언가를 쓴 건지 알 수는 없지만 여튼 재미있었다. 여러 형태로 체크해 볼 수 있는 표를 쉽게 만들어 주는 거니까.
제3자 입장에서 분석한다면
1번 분기요인은 조금 애매하다. 독립변수인 분기요인과 월 요인이 사실 매우 높은 상관관계가 있기 때문이다. 이게 어떤 모델을 이용해서 어떤 형태로 데이터를 분석했는지 모르는 이상 매 년도의 월별 요인을 확인해 봐야 할 듯 하다.
2번 할인도 애매하다. 할인 유무에 따라 매출액 감소량 차이가 나긴 하는데 저게 크리티컬한지는 도메인 지식이 있어야하고, 다른 변수도 좀 봐야겠다.
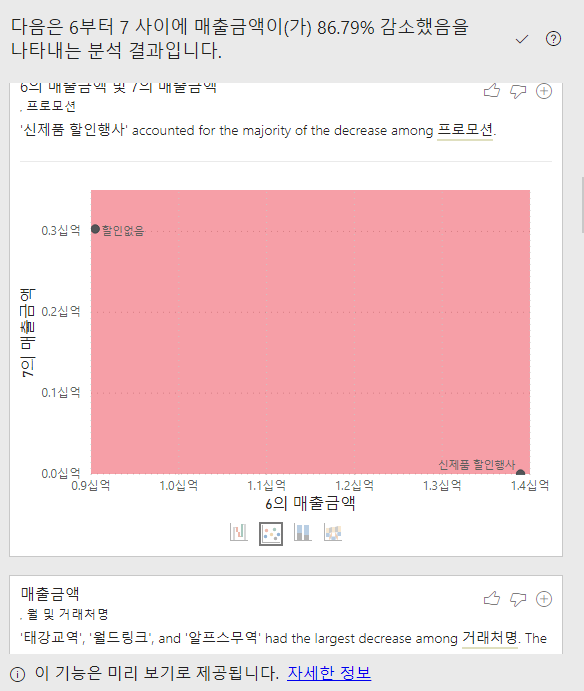
3번 와 이건 아예 모르겠다. 거래처 다 줄었는데 특히 많이 줄어든 거래처가 위에 있을 뿐인 것 같다.

생각보다 산점도가 많은 정보를 주는 것 같다. 전반적으로 회귀선 근처에 있는 것 같긴한데,
6월 행사, 7월 행사 종료인 것을 보면 우측에 있는 그룹들이 할인행사에 대한 탄력석이 높은 업체로 보인다. 오프라인 판매점이라고 가정했을 때, 원점에 가까운 곳들은 원래 매출액 자체가 적고, 우측 하단에 있는 업체들은 지역의 소득이 상대적으로 낮은 곳일 수도 있을 것 같다. 상세한건 지역별 매출액 변화를 보면 되겠지만 대충 그정도로 예측하겠다.
유미백화점은 오히려 할인 행사 때 덜 번 신기한 곳이다. 이정도 디테일이면 가상 데이터 보단 실제 데이터를 레이블링을 바꾼게 아닐까 싶다. 저기는 가격이 비싸야 좋은 제품으로 평가하는 고객들이 주로 가는 곳이 아닐까 싶다. 스눕 효과가 있으려나...?
4번 제품명 변수 얘는 시작부터 특정 품목이 확 뛴다. 산점도도 한 번 볼까?

다른 애들은 매출액 차이가 그리 크지 않은데 52인치 HDTV 매출액 차이가 많이 난다. 위 내용과 연계했을 때 아마 저게 신제품이고, 프로모션을 진행하던 제품이 아닐까...? 라는 합리적 의심을 할 수 있을 것 같다.
하락말고 이전 달의 상승 요인을 보면 조금 더 연속적인 해석이 가능하지 않을까?
 |
 |
 |
 |
1번 거래처 변수는 예상했던대로 매출이 많이 줄었던 업체들이 6월에 사실은 엄청 매출이 뛰었던 업체들이었다. 단순히 못팔아서라기보다는 프로모션 활용을 엄청 잘 했거나, 그런 고객들이 많은 지역일 수 있다.
2번 제품명 말고 제품 분류다. 음... 이것도 해석하려면 도메인 지식이 필요할 것 같긴 한데, 내 가구팔이 경험으로 봤을 땐 할인액 보고 들어왔다가 그래도 비싸서 다른 제품들을 샀을 가능성이 높은 것 같다. 3번에 제품명을 주요 요소로 잡았음에도 제품분류가 주요 요소로 잡힌다는 것은 이유가 있을 것 같다.
(반대경우에는 상위에 잡히지 않았다. 아무리 생각해도 DT계열의 냄새가 짙게 난다.)
3번... 네 예상대로 6월 매출이 크게 오른 제품이다. 프로모션을 했을 거라는 추측이 킹리적 갓심으로 변하는 순간이다.
4번 분기 요인이 실제로 있었던 건지 확인할 수 있는 년도 변수다. 매년 증가하다가 2015년에만 갑자기 감소했다. 전월대비로는 증가했지만 전년 대비로는 감소한 듯 하다. 경기가 안좋았는데도 프로모션빨로 상당히 선방했다는 말이 될 수 있다. 그러다 프로모션 끝나니 매출이 훅 감소한 것 같다.
현실에서 보고할 때 상황을 생각해보면 정말 재미있을 것 같다.

부서별로 TV 사업부 탓이니, 마케팅 부서 때문이니, 경기 때문이니 온갖 이야기들이 나올텐데...
분석 기능으로 좀 더 쉽게 알아볼 수 있을 것 같다.
7. 인공지능은 역시 설명력에서 조금 아쉬움이 있다. 저기서 한 단계 더 나간게 신기능인 분해 트리다.

할인율은 동일하게 20% 씩이었고, 신기하게 동일 제품인데 할인없이 판 것도 있더라... 전산 입력 잘못한건가... 저런거 클레임 걸리면 엄청 피곤한데...
요약 : 분석 -> 분해트리 콤보가 너무 좋다. 저거 직접 코드 짜려면 정말 피곤한데... 태블로는 안써봐서 모르겠는데 이 기능 정말 마음에 든다. 저걸 데이터 분석가 한 명이 하려면 데이터 전체 구조를 이해한 상태에서 일일이 머신러닝 가능한 형태로 전부 바꾸고... 그걸로 러닝 돌린 뒤에 순서대로 각 변수별로 그래프 그려가며 찾아야 되는데 보고싶은대로 클릭 드래그만으로 찾아 볼 수 있다. 메뉴 좀 복잡하면 어떠랴... 정말 맘에 든다.
컴퓨터 사용에 익숙한 경영자라면 이정도는 직접 다뤄볼 수 있지 않을까 싶다.
'반치용 > 기타 및 저장' 카테고리의 다른 글
| [저장]딥러닝 최적화 관련 (0) | 2020.03.29 |
|---|---|
| [nlp] 데이터 저장소 (0) | 2020.02.28 |
| [저장] 데이터 둘러보기 (0) | 2020.01.21 |
| [중요]XGBoost 개념 및 전반적인 내용 (0) | 2020.01.20 |
| [저장]자유도에 관해 (0) | 2020.01.20 |
댓글