array1 = [1,2,3,7,4,234,3,7,8]
print(array1[:])
array2 = np.sort(array1)
print(array2[:])
array3 = array1.sort()
print(array1[:])np.sort(배열) : 원본은 두고, 배열한 값만 반환
배열.sort() : 반환값이 없고 원본 배열의 순서를 정렬함
np.array() 의 활용
np.array(배열, axis=0) : 세로 방향 정렬(각각 별도로)
np.array(배열, axis=1) : 가로 방향 정렬(각각 별도로)

np.argsort(배열) : 정렬 후 원본 기준 순서(인덱스값) 반환
np.dot(행렬1,행렬2) : 행렬 내적(행렬 곱)
np.transpose(행렬) : 행렬의 전치행렬.
파일 불러오기
import pandas as pd
df_titanic = pd.read_csv("경로/파일명")크기 확인
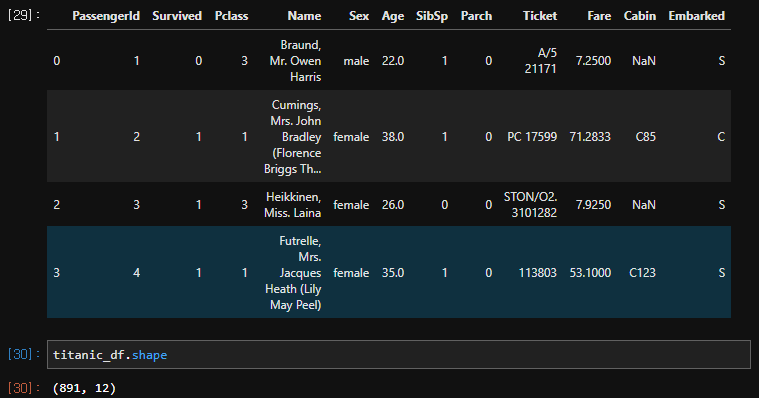
df.shape : 행 수, 열 수 꼴로 결과 반환
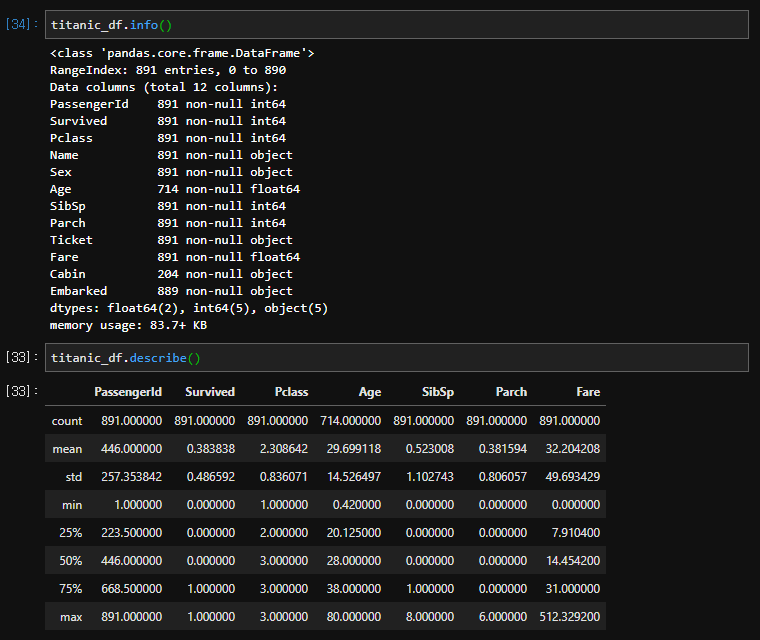

☆☆☆☆☆이거 엄청 중요함☆☆☆☆☆
df.value_count() : 값 별로 숫자가 얼마나 되는지 세어줌 (R의 table과 같은 역할) 자주 쓰게 됨
유사한 기능으로는 crosstab 함수가 있다
참고 : https://3months.tistory.com/194?category=753896
R의 mutate 기능 하는 법 :
titanic_df['Family_Number'] = titanic_df['SibSp']+titanic_df['Parch'] +1
인덱스 추출(row name 추출)
titanic_df.index
인덱스값을 array로 반환
titanic_df.index.values
dataframe 인덱싱은 눈으로 보고 넘어감. 패스
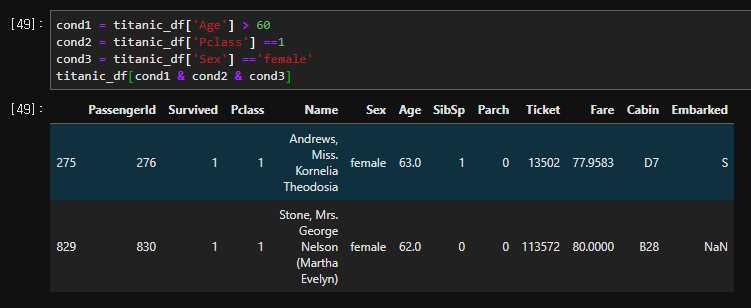
정렬
titanic_sorted = titanic.sort_values(by=['Pclass','Name'], ascending=True)
그룹 및 집계
agg_format={'Age':'max','SibSp':'sum','Fare':'mean'}
titanic_df.groupby('Pclass').agg(agg_format)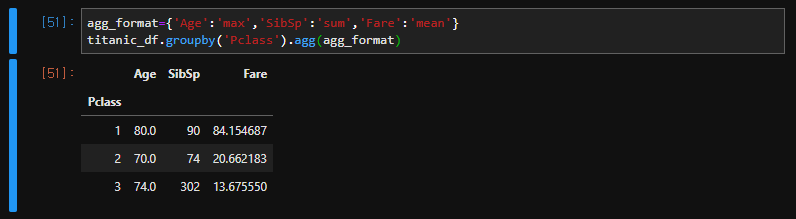
titanic_df.groupby('Pclass')['Age'].agg([max,min])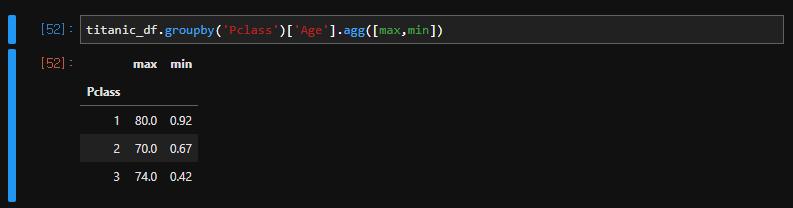
'반치용 > 기타 및 저장' 카테고리의 다른 글
| [파이썬 머신러닝] day 003 - pandas 끝 (0) | 2019.12.25 |
|---|---|
| 생존분석 & P-value 등 (0) | 2019.12.23 |
| [논문]Network Decomposition into Fixed Points of DegreePeeling-필링(Peeling) 관련 (0) | 2019.12.16 |
| [파이썬 머신러닝]시작(day001) (0) | 2019.12.15 |
| 파이썬 시각화 (0) | 2019.12.15 |


댓글